Балансировка виртуальных машин.
Если вы желаете получить Живую Миграцию виртуальных машин среди нод кластера, вам необходим некий общий ресурс. Для кластера виртуализации ProxmoxVE, использующий Linux KVM, мы с коллегами решили выбрать в качестве Системы Хранения Данных (СХД) - Ceph. Так как виртуальные жёсткие диски будут представлены объектами в кластере Ceph, то сразу становится понятно, что виртуальный диск виртуальной машины - это прежде всего связь по сети. Узнаем какая виртуальная машина сколько читает и пишет байт, сможем разнести виртуальные машины по физическим нодам кластера.
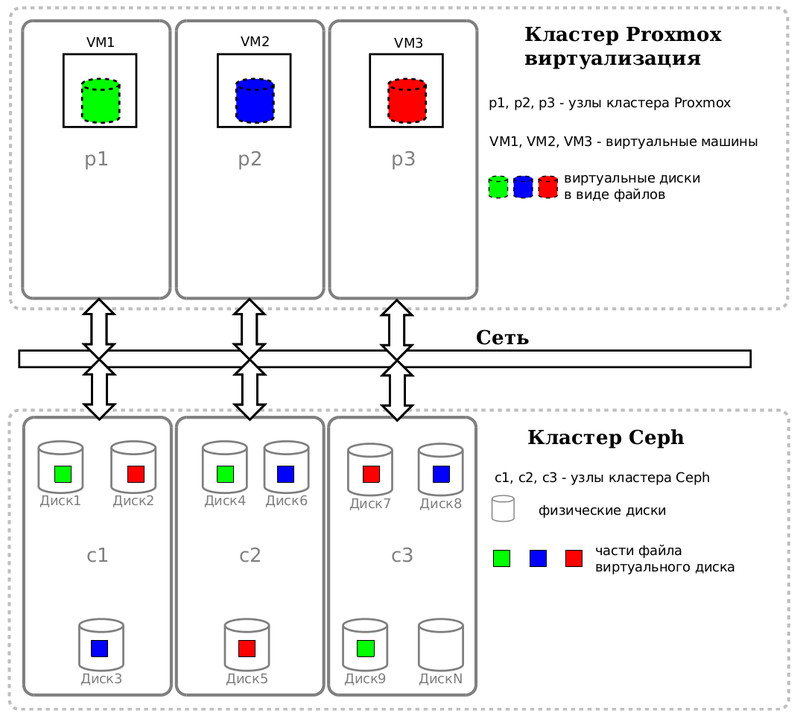
Страсть как захотелось узнать I/O каждой виртуальной машины, а другими словами - количество байт, отправленных нодой Proxmox ноде Ceph'а. И не просто узнать, а выдать рекомендацию по размещению виртуальных машин на различных нодах кластера ProxmoxVE, исходя из нагрузки. Очень не хотелось бы, чтобы сетевая карта какой-либо ноды отлынивала от работы.
Если вместо слова сервер произнести слово куча, а вместо "виртуальные машины с различающимся I/O" - камни, то вспомнилась Задача о камнях. Нужно распределить N объектов (камней), каждый со своим весом, по M группам (кучи) так, чтобы суммарные объёмы групп были по возможности равны.
Это, наверное, первый случай, когда так явно понадобилось вспомнить годы учёбы. Я чуток схитрил и взял из всех методов жадный алгоритм: на каждом шаге будем брать самый тяжёлый камень из оставшихся и кладём в самую "лёгкую" кучу.
Но прежде чем приступить к описанию моего поделия хочется:
- Извиниться, что всё далее будет написано на топорном скриптом языке. Я админ и этим всё сказано.
- Данное решение не выполняет каких-либо автоматических действий. Просто расчёт и выдача рекомендации по разнесению виртуальных машин по нодам кластера, основываясь на реальных показаниях.
Так как ProxmoxVE - Debian с человеческим лицом по управлению виртуальными машинами, то под капотом у него KVM + Qemu. Для автоматизации управления Qemu есть протокол под названием QEMU Machine Protocol (QMP), основывающийся в своей работе на JSON. Работать с JSON в bash скриптах - изврат ещё тот, но я уже извинился =).
Первый скрипт get_metrics.sh получает статистику по блочным устройствам работающих виртуальных машин на данной ноде. В цикле for обходим по всем конфигурационным файлам виртуальных машин, работающие на данной ноде в данный момент времени. ProxmoxVE любезно их предоставляет в каталоге /etc/pve/qemu-server/
#!/bin/bash
# Welcome to vasilisc.com
QEMU_MONITOR_SOCKET_PATH=/var/run/qemu-server
QEMU_MONITOR_SOCKET_EXT=qmp
SOCAT=$(which socat) || { echo "socat cmd not found => exit"; exit 1; }
# В цикле for обходим по всем конфигурационным файлам виртуальных машин данной ноды.
# ProxmoxVE любезно их предоставляет в каталоге /etc/pve/qemu-server/
for f in `ls -1 /etc/pve/qemu-server/`; do
# получаем VMID из имени конфигурационного файла - 100.conf даст 100
VMID=$(basename "${f}" .conf)
# получаем имя виртуальной машины, так как просто работать с VMID достаточно сложно
nameVM=`cat /etc/pve/qemu-server/${VMID}.conf | grep name | cut -d":" -f2 | tr -d ' '`
# В заранее созданном qmp_commands.txt две строки с командами
# { "execute": "qmp_capabilities" }
# { "execute": "query-blockstats" }
cat qmp_commands.txt | ${SOCAT} unix-connect:${QEMU_MONITOR_SOCKET_PATH}/${VMID}.${QEMU_MONITOR_SOCKET_EXT} stdio > ${VMID}.json
# Из JSON делаем plain text file для удобного парсинга в скрипте =) .
cat ${VMID}.json | tr ',' '\n' | awk '{ gsub(/[\{\}\[\]]/, "\n&\n"); print }' | grep -ve '^ *$' | grep -vF ": 0" | grep -E "(wr_|rd_)" | sort -u > ${VMID}${nameVM}.stat
done
# копируем полученные файлы .stat на компьютер, который будет производить анализ всех stat файлов
# в данном случае scp использует ключи для копирования файлов без запроса пароля
scp *.stat user@IP_address:/statistics/
exit 0
Этот скрипт get_metrics.sh растиражирован на все ноды ProxmoxVE и будет запускаться в ручную или в планировщике cron, после разрешения проблем в полными путям в скрипте.
Теперь нужен второй скрипт, анализирующий файлы stat и выдающий рекомендации. Измените переменную NODES=(0 0 0) и укажите столько нулей, сколько у вас нод.
#!/bin/bash
# vasilisc 2014
# получить статистику по виртуальным машинам (ВМ) - активность блочных устройств (дисков)
# в идеале самые активные ВМ - нужно разнести по разным нодам
clear
dateevent=`date +'%Y%m%d_%H%M'`
# Сколько нод-серверов (кучи) - столько должно быть нулей
NODES=(0 0 0)
# Чистимся
:>tmp1.txt
:>tmp2.txt
:>tmp3.txt
# Обходим файлы stat
for f in `ls -1 *.stat`; do
# получаем VMID из имени файла
VMID=$(basename "${f}" .stat)
# Берём кол-во считанных байт rd_bytes
# Трюк с суммированием awk '{sum+=$1}END{print sum}' помогает если у виртуальной машины
# несколько виртуальных дисков
rd=`cat ${f} | grep -F "rd_bytes" | cut -d":" -f2 | tr -d ' ' | awk '{sum+=$1}END{print sum}'`
# Бешеное число байт превращаем в мегабайты, деля на 1024*1024
rd=$(echo "scale=0;$rd/1048576"|bc)
echo "${VMID} ${rd}" >> tmp1.txt
# Берём кол-во записанных байт wr_bytes
wr=`cat ${f} | grep -F "wr_bytes" | cut -d":" -f2 | tr -d ' ' | awk '{sum+=$1}END{print sum}'`
# Бешеное число байт превращаем в мегабайты, деля на 1024*1024
wr=$(echo "scale=0;$wr/1048576"|bc)
echo "${VMID} ${wr}" >> tmp2.txt
# Сумма считанных и записанных
sum_rd_wr=$(($rd + $wr))
echo "${VMID} ${sum_rd_wr}" >> tmp3.txt
done
# сортировка по убыванию
cat tmp1.txt | sort -r -k2 -n > read_${dateevent}.txt
cat tmp2.txt | sort -r -k2 -n > write_${dateevent}.txt
cat tmp3.txt | sort -r -k2 -n > readwrite_${dateevent}.txt
sync
# используем жадный алгоритм "Задачи о камнях" для балансировки ВМ по нодам кластера
i=0
while read namevm valio
do
NAME[$i]=$namevm
VAL[$i]=$valio
i=$(expr $i + 1)
done < readwrite_${dateevent}.txt
COUNTVM=${#NAME[@]}
COUNTNODES=${#NODES[@]}
for (( j=0;j<$COUNTVM;j++)); do
# ищем позицию минимума среди массива NODES
pos_min=`echo "${NODES[@]}" | tr -s ' ' '\n' | awk '{print($0" "NR-1)}' | sort -g -k1,1 | head -1 | cut -f2 -d' '`
# увеличиваем элемент массива на величину I/O ВМ
NODES[${pos_min}]=$(echo "scale=2;${NODES[${pos_min}]} + ${VAL[${j}]}"|bc)
RNODES[${j}]=${pos_min}
done
# выводим имя виртуальной машины - значение её read+write - цифра рекомендованной ноды
# на которой желательно запустить данную ВМ
for (( j=0;j<$COUNTVM;j++)); do
echo "${NAME[${j}]} ${VAL[${j}]} ${RNODES[${j}]}" >> readwrite_${dateevent}_balance.txt
done
exit 0
Теперь у меня есть скрипт, которая будет выдавать рекомендации, основываясь на реальной нагрузке, а не на ощущениях админа. Тем более, в будущем количество виртуальных серверов (камней) вырастет, увеличится количество физических серверов (куч) и всегда меняется нагрузка I/O (вес камней).
Дополнительные материалы:
Оптимизация гостевых операционных систем KVM.
Интересные факты о Debian Linux.
Как работает Proxmox с Ceph. RBD.
