Журналы Postfix в ElasticSearch.
Многие админы слышали об ElasticSearch - свободной поисковой системе, основанной на Lucene. Несмотря на недоверие хейтеров Java, ElasticSearch реально быстр в плане поиска и анализа информации, которую вы поместили в базу ES. Много лет уже ElasticSearch нам помогает в работе: есть у нас и удалённый syslog сервер и успешно опробованный netflow сервер (коллектор + система обработки и представления данных). Часто требуется в админской практике что-то поискать в журнале Postfix. Даже вспомогательными скриптами тяжело grep'пить multiline журналы, хотелось бы по-современному загонять их в некую базу и потом там легко искать нужное, строить графики, проводить аналитику и т.д.
Постановка задачи
Благодаря грамотной архитектуре почтового сервера Postfix достигается безопасность и надёжность, но небольшой платой за спокойствие является сложность разбора журнала работы Postfix. Различные даемоны Postfix пишут нужную тебе информацию о происходящей SMTP сессии в виде множества строк, которые хотелось красиво разобрать (parse) и проанализировать.
Упрощённый пример SMTP сессии Postfix из текстового журнала.
Apr 7 11:54:54 mail postfix/smtpd[23202]: ACE141C020C: client=pc1.example.com[10.1.2.3]
Apr 7 11:54:54 mail postfix/cleanup[24213]: ACE141C020C: message-id=<f47ee90f5429@example.com>
Apr 7 11:54:54 mail postfix/qmgr[1485]: ACE141C020C: from=<firma@example.com>, size=928, nrcpt=2 (queue active)
Apr 7 11:54:55 mail postfix/smtp[24215]: ACE141C020C: to=<user1@gmail.com>, relay=gmail.1.google.com[173.194.220.1]:25, delay=0.91, delays=0.28/0.2/0.1/0.32, dsn=2.0.0, status=sent (250 2.0.0 OK 1616835295 m14si10145180lfh.102 - gsmtp)
Apr 7 11:54:57 mail postfix/qmgr[1485]: ACE141C020C: removed
Старая попытка занесения журналов Postfix в MySQL
Скажу честно, но в старые времена, до моего знакомства с ElasticSearch, была создана простая php формочка, которая делала запрос к базе данных MySQL куда данные заносились из журнала Postfix топорным bash скриптом. В целом всё работает, но нет желания развивать своё поделие, так как всё равно не приблизиться к мощи стека ElasticSearch + LogStash + Kibana (ELK), к его скорости, к его функционалу.
Через php + MySQL мною реализовано почти всё не правильно. В реальной жизни человек может указать множество адресатов в одном письме и в рамках SMTP сессии вы увидите множество to=. В реляционных базах данных это намекает на создание дополнительной таблицы, связанной с основной таблицей отношением один-ко-многим (One-to-Many). Я совсем не парсил строки и не вычленял нужные поля, чтобы занести их по правилам реляционных БД, а просто выуживал из строки дату-время, номер очереди и всё остальное "превращалось" в сообщение. Путеводной звездой, объединяющей множество строк уже в таблице оставалось имя очереди, которое уникально.
Вот структура единственной таблицы
CREATE TABLE postfixmaillog (
dateevent datetime NOT NULL,
namequeue varchar(20) NOT NULL,
textmsg text NOT NULL
)
Остальное извращение с поиском нужного было уже в скрипте php, который формировал и выводил информацию в более-менее приглядной форме. Это было лучше ползанья grep'ом и/или скриптами на самом сервере, но, в целом, оставалось парашей, за которую не испытываешь гордости. Ни какой аналитики и любых других хотелок не было и нужно было допиливать php скрипт. Даже чужие наработки, найденные на просторах Интернет, классически сковывали своим интерфейсом желание сделать какой-либо свой запрос и построить по нему какой-либо график и т.д.
Занесение журналов Postfix в ElasticSearch
ElasticSearch - это по сути своей база данных, но она не собирается сама чудесным способом парсить логи и вычленять из строк нужные поля. Значит вопрос остался открытым - как красиво распарсить множество строк в журнале, где путеводной звездой есть только уникальный номер очереди?
Как Чип и Дейл, нам на помощь спешит плагин Aggregate filter в LogStash, который традиционно занимается приёмом данных от различных источников, парсингом и занесением информации собственно в базу ElasticSearch.
Целью фильтра является, как понятно из его названия, агрегирование информации, доступной среди нескольких событий (обычно строк журнала), принадлежащих одной и той же задаче, и, наконец, формирование агрегированной информации в окончательное событие задачи. Есть масса ньюансов, но на примере обычной SMTP сессии, вы, как человек, понимаете что после подстроки ACE141C020C: client= началась новая сессия и она закончилась после подстроки ACE141C020C: removed. Даже если правильно предположить что строки могут "разбавляться" строками другой SMTP сессии, можно разобраться что и где по уникальному номеру очереди. Такое и позволяет запрограммировать Aggregate filter.
Все файлы-наработки вы найдёте в конце статьи. Далее будут выдержки для понимания как всё работает в данный момент.
Ложка дёгтя
К сожалению, фильтр агрегирования вынуждает вас убить напрочь параллельность от слова совсем. Вы обязаны выставить pipeline.workers: 1 в /etc/logstash/logstash.yml
Дело в том, что если множество потоков LogStash начнут получать строки, то они будут раскиданы по разным потокам, которые не смогут собрать итоговое событие, так как не делят между собой информацию.
Это настолько важный момент, что вам стоит трижды подумать над этим, даже если вас очень заинтересовала тема статьи. Чтобы не убивать производительность для текущих задач, придётся, возможно, делать отдельный сервер LogStash под приём журналов Postfix.
Отправка и приём логов
Для отправки журналов с почтового сервера достаточно добавить на нём в файле /etc/rsyslog.d/postfix.conf строку
mail.* @@10.1.2.3:10555
где:
- @@ - означает использовать TCP протокол. Настоятельно рекомендую использовать TCP с гарантией доставки информации.
- 10.1.2.3 - IP адрес вашего сервера LogStash
- 10555 - выбранный вами произвольный, свободный порт выше 1024
После рестарта службы sudo systemctl restart rsyslog ваш почтовик начнёт слать логи на remote syslog LogStash, которые пока временно никто не принимает.
На сервере LogStash 10.1.2.3 в файле /etc/logstash/conf.d/postfix-syslog.conf начинаем формировать первую нужную часть input для приёма логов.
Вся часть input (нажмите для раскрытия списка)
# begin input
input {
# в бою
udp {
type => syslog
port => 10555
}
# для отладки (в файле должна быть отдельная последняя пустая строка)
#file {
# path => "/tmp/testmail.log"
# start_position => "beginning"
# sincedb_path => "/dev/null"
# ignore_older => 0
#}
}
# end input
Парсим и фильтрируем
Для правильной работы нам потребуется пара переменных. В файле /etc/logstash/patterns.d/postfix-patterns должны быть строки
SYSLOGTIMESTAMP %{MONTH} +%{MONTHDAY} %{TIME}
POSTFIX_MSG_ID [0-9A-F]{10,11}
Вся часть filter (нажмите для раскрытия списка)
# begin filter
filter {
# начинаем парсинг
if [type] == "syslog" and [message] =~ "postfix" {
#if [message] =~ "postfix" {
# мешают парсить не нужные строки - drop
# 1 мешает PIX - нет дополнительной информации и мешает секции if postfix/smtp
# postfix/smtp[8026]: E854E1C0848: enabling PIX workarounds: disable_esmtp for mail.almaz.ru[1.2.3.3]:25
if [message] =~ "PIX" { drop {} }
# 2 не нужен вывод policy-spf
# postfix/policy-spf[29399]: Policy action=DUNNO
if [message] =~ "postfix/policy-spf" { drop {} }
# 3 удаляем bounce - так как не знаем как корректно связать две очереди в строках уведомления. Само встречное письмо о доставке обрабатывается корректно
# postfix/bounce[1736]: 640A31C0848: sender non-delivery notification: 235071C085B
if [message] =~ "postfix/bounce" { drop {} }
# 4 удаляем warning по поводу отсутствия записей A PTR у спам сессий. Postfix позже всё равное сделает NOQUEUE
# postfix/smtpd[20313]: warning: hostname
if [message] =~ "warning: hostname" { drop {} }
# 5 удаляем статистику от Postfix session count and request rate control
# postfix/anvil[23300]: statistics: max connection rate 2/60s for (smtp:8.183.149.173) at Jul 21 06:18:06
# postfix/anvil[23300]: statistics: max connection count 2 for (smtp:9.255.91.105) at Jul 21 06:21:53
# postfix/anvil[23300]: statistics: max cache size 3 at Jul 21 06:18:34
if [message] =~ "postfix/anvil" { drop {} }
# 6 удаляем строки не созданных SMTP сессий и вышедших по таймаутам ... всё равно номера SMTP сессии - нет
# postfix/smtpd[27347]: timeout after END-OF-MESSAGE from ...
# postfix/smtpd[11696]: timeout after NOOP from ...
if [message] =~ "timeout after" { drop {} }
# конец drop
# список шаблонов для парсинга SMTP сессии Postfix
grok {
patterns_dir => ["/etc/logstash/patterns.d/"]
match => {
"message" => [
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{POSTFIX_MSG_ID:taskid}: client=(?<client_hostname>[^\]]+)\[%{IP:client_ip}\]",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{POSTFIX_MSG_ID:taskid}: message-id=<(?<message_id>[^>]+)>.*",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{POSTFIX_MSG_ID:taskid}: from=<(?<t>(?<from_mail>[^>]+)?)>, size=%{INT:size}, nrcpt=%{INT:nrcpt}.*",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{POSTFIX_MSG_ID:taskid}: to=<(?<to_mail>[^>]+)>,.* relay=%{NOTSPACE:relay},.* status=%{NOTSPACE:status} \((?<status_msg>.+)\).*",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{POSTFIX_MSG_ID:taskid}: removed",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{POSTFIX_MSG_ID:taskid}: milter-reject: (?<status>END-OF-MESSAGE) from (?<client_hostname>[^\]]+)\[%{IP:client_ip}\]: (?<status_msg>.+); from=<(?<from_mail>[^>]+)> to=<(?<to_mail>[^>]+)>.*",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{DATA:taskid}: (?<status>.+):.*from %{DATA:client_hostname}\[(?<client_ip>%{IP})\]: %{DATA:status_msg}; from=<(?<t>(?<from_mail>[^>]+)?)> to=<(?<to_mail>[^>]+)>.*",
"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:program}(?:\[%{POSINT:syslog_pid}\])?: %{NOTSPACE:status}: %{POSTFIX_MSG_ID:taskid}: (?<status_msg>.+)"
]
}
}
# end grok
# если нет имени очереди, то MTA отверг (reject) письмо, не создав SMTP сессию с taskid
# postfix/smtpd[25614]: NOQUEUE: reject: RCPT from ....
if [taskid] == "NOQUEUE" {
mutate {
remove_field => ["host", "message", "beat.version", "beat.hostname", "prospector.type", "input.type", "offset", "type", "t", "event"]
add_tag => [ "postfix" ]
convert => [
"size", "integer",
"nrcpt", "integer",
"syslog_pid", "integer"
]
}
} else if [program] == "postfix/smtpd" and [client_ip] {
# все входящие сессии (из Интернет или наши пользователи) обладают строкой кто именно к нам подсоединился - создаём карту create_or_update
# postfix/smtpd[12406]: connect from mail.almaz.ru[1.2.3.4]
aggregate {
task_id => "%{taskid}"
code => "
map['debug'] ||= [];
map['debug'] << 1;
map['client_hostname'] ||= event.get('client_hostname')
map['client_ip'] ||= event.get('client_ip')
map['program'] ||= event.get('program')
event.cancel()
"
map_action => create_or_update
}
} else if [program] == "postfix/cleanup" and [message_id] and ![status] {
# когда сам сервер пишет письмо-уведомление-о-доставке, то нет никакого коннекта к нам - создаём карту create_or_update
# postfix/cleanup[25466]: FFFFE1C0848: message-id=<ss777@mail.your-domain.ru>
aggregate {
task_id => "%{taskid}"
code => "
map['debug'] ||= [];
map['debug'] << 2;
map['message_id'] ||= event.get('message_id')
event.cancel()
"
map_action => create_or_update
}
} else if [program] == "postfix/qmgr" and [nrcpt] {
# В письме должно быть указание КТО написал письмо или <> NULL SENDER, который ниже заменим на NULL_SENDER_RFC5321 - обновляем карту
# postfix/qmgr[1788]: 5A05E1C053C: from=<user@domain.ru>, size=1333858, nrcpt=1 (queue active)
# postfix/qmgr[1788]: FFFFE1C0848: from=<>, size=4353, nrcpt=1 (queue active)
aggregate {
task_id => "%{taskid}"
code => "
map['debug'] ||= [];
map['debug'] << 3;
map['from_mail'] ||= event.get('from_mail')
if map['from_mail'].nil?
map['from_mail'] = 'NULL_SENDER_RFC5321'
end
map['size'] ||= event.get('size')
map['nrcpt'] ||= event.get('nrcpt')
event.cancel()
"
map_action => update
}
} else if ( [program] == "postfix/smtp" or [program] == "postfix/virtual" ) {
# доставка письма если внешнему серверу (OUT), то smtp. А если письмо нам (IN), то virtual. обновляем карту
# postfix/smtp[24636]: 6F7971C048F: to=<external-user@gmail.com>, relay=gmail-smtp-in.l.google.com[142.250.102.27]:25, delay=3.1, delays=0.63/0/1.8/0.59, dsn=2.0.0, status=sent (250 2.0.0 OK 111132 x15-20020 - gsmtp)
# postfix/virtual[27549]: 0FA4D1C0520: to=<your-user@your-domain.ru>, relay=virtual, delay=0.53, delays=0.44/0.01/0/0.08, dsn=2.0.0, status=sent (delivered to maildir)
aggregate {
task_id => "%{taskid}"
code => "
map['debug'] ||= [];
map['debug'] << 4;
map['to_mail'] ||= [];
map['to_mail'] << event.get('to_mail');
map['relay'] ||= [];
map['relay'] << event.get('relay');
map['status'] ||= [];
map['status'] << event.get('status')
map['status_msg'] ||= [];
map['status_msg'] << event.get('status_msg')
event.cancel()
"
map_action => update
}
} else if ( ( [program] == "postfix/qmgr" and ![nrcpt] ) or ( [program] == "postfix/cleanup" and [status] ) or ( [program] == "postfix/smtpd" and [status_msg] ) ) {
# нормальная SMTP сессия заканчивается ( qmgr И нет nrcpt )
# postfix/qmgr[1788]: FFFFE1C0848: removed
# ИЛИ
# сессию прекратил milter И вынес вердикт по спаму и вирусам
# postfix/cleanup[29093]: 153E31C03DF: milter-reject:
# закрываем карту
# ИЛИ
# Postfix прекратил сессию из-за превышения различных лимитов
# postfix/smtpd[703]: warning: 097781C053C: queue file size limit exceeded
aggregate {
task_id => "%{taskid}"
code => "
map['debug'] ||= [];
map['debug'] << 5;
map['status'] ||= [];
map['status'] << event.get('status')
map['from_mail'] ||= event.get('from_mail')
map['to_mail'] ||= [];
map['to_mail'] << event.get('to_mail');
map['status_msg'] ||= [];
map['status_msg'] << event.get('status_msg')
event.set('debug',map['debug']);
event.set('client_hostname',map['client_hostname']);
event.set('client_ip',map['client_ip']);
event.set('from_mail',map['from_mail']);
event.set('size',map['size']);
event.set('nrcpt',map['nrcpt']);
event.set('to_mail',map['to_mail']);
event.set('relay',map['relay']);
event.set('status',map['status']);
event.set('status_msg',map['status_msg']);
event.set('program',map['program']);
event.set('message_id',map['message_id']);
"
map_action => update
end_of_task => true
timeout_task_id_field => "taskid"
timeout_timestamp_field => "@timestamp"
timeout => 346000
push_map_as_event_on_timeout => false
push_previous_map_as_event => false
timeout_tags => ['_aggregatetimeout']
}
# end aggregate
mutate {
convert => [
"size", "integer",
"nrcpt", "integer",
"syslog_pid", "integer"
]
remove_field => ["host", "message", "beat.version", "beat.hostname", "prospector.type", "input.type", "offset", "type", "t", "event"]
add_tag => [ "postfix" ]
}
}
# end if else ALL
}
# end if message postfix
}
# end filter
Важная часть - это фильтр и в нём легендарный grok. Вы можете найти в Интернет массу онлайн ресурсов в помощь, но даже в самой Kibana есть Dev Tools - Management - Grok Debugger, который поможет создать и проверить ваше регулярное выражение на разбор конкретной строки.
Grok всего лишь парсит приходящие строки и находит нужное, заполняя нужные поля. Магия сбора в единое целое происходит с помощью фильтра агрегирования.
- Если начнётся SMTP сессия нормального письма, то через grok правило
%{POSTFIX_MSG_ID:taskid}: client=(?<client_hostname>[^\]]+)\[%{IP:client_ip}\]
пройдёт строка
ACE141C020C: client=pc1.example.com[10.1.2.3]
и сработает ветка if [program] == "postfix/smtpd" and [client_ip]
мы создаём (map_action => create_or_update) новую карту (map), агрегируя по уникальному номеру очереди taskid. -
Если отправитель попросил уведомить его о доставке письма, то Postfix напишет встречное письмо, которое
1) к сожалению для нас НЕ начинается как обычное нормальное письмо со слова client (так как это мы и начали сессию)
2) в качестве отправителя используется по стандарту RFC 5321 from=<> (NULL SENDER) для предотвращения email loop между почтовыми серверами.Ответное письмо выглядит так
D826F1C060C: message-id=<20210330140158.D826F1C060C@mail.example.com>
D826F1C060C: from=<>, size=5727, nrcpt=1 (queue active)
D826F1C060C: to=<user@firma.ru>, relay=mx1.firma.ru[1.21.98.74]:25, delay=0.63, delays=0.03/0.01/0.11/0.47, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued as 6BA9620003)
D826F1C060C: removedПоэтому нам нужна ветка if [program] == "postfix/cleanup" and [message_id] and ![status], которая так же создаёт (map_action => create_or_update) новую карту (map), агрегируя по уникальному номеру очереди taskid.
Эта же ветка поможет обновить карту в рамках нормального письма.
-
В рамках SMTP сессии нормального письма придёт строка
ACE141C020C: from=<firma@example.com>, size=928, nrcpt=2 (queue active)
которую пропустит grok правило
%{POSTFIX_MSG_ID:taskid}: from=<(?<from_mail>[^>]+)>, size=%{INT:size}, nrcpt=%{INT:nrcpt}.*
и сработает
if [program] == "postfix/qmgr" and [nrcpt]
где мы просто обновляем карту (map_action => update) дополнительными данными. -
В рамках SMTP сессии "нормального" письма придёт строка и не ОДНА!
ACE141C020C: to=<user1@gmail.com>, relay=gmail.1.google.com[173.194.220.1]:25, delay=0.91, delays=0.28/0.2/0.1/0.32, dsn=2.0.0, status=sent (250 2.0.0 OK 1616835295 m14si10145180lfh.102 - gsmtp)которую пропустит grok правило
%{POSTFIX_MSG_ID:taskid}: to=<(?<to_mail>[^>]+)>,.* relay=%{NOTSPACE:relay},.* status=%{NOTSPACE:status} \((?<status_msg>.+)\).*и сработает
if ( [program] == "postfix/smtp" or [program] == "postfix/virtual" )
где мы просто обновляем карту (map_action => update) дополнительными данными.Строки кода на языке Ruby
map['to_mail'] ||= [];
map['to_mail'] << event.get('to_mail');следует читать так - создай массив если не создано и пополни полученным.
В данном месте специалист по реляционным базам данных поймёт без слов что на лицо нарушение Первой Нормальной Формы. В одном поле находится не скалярное значение, а массив.
-
Нормальное письмо заканчивается так - ACE141C020C: removed
а заблокированное почтовым фильтром (mail filter, milter) примерно так (придётся адаптировать под вашу систему фильтрации, если она используется)
34EBB1C0617: milter-reject: END-OF-MESSAGE from mail.evilsite.com[95.14.15.1]: 5.7.1 Command rejected; from=<badletter@evilsite.com> to=<user@firma.ru> proto=ESMTP helo=<mail.evilsite.com>Срабатывает ветка if ( ( [program] == "postfix/qmgr" and ![nrcpt] ) or ( [program] == "postfix/cleanup" and [status] ) or ( [program] == "postfix/smtpd" and [status_msg] ) )
Мы обновляем карту (map_action => update) окончательно формируем событие (event.set) и завершаем задачу (end_of_task => true).
Мы даём 4 дня (60 * 60 * 24 * 4 ~= 346000 секунд) по RFC на SMTP сессию (timeout => 346000), что порождает проблемы более при длительных SMTP сессиях, например в случае проблем с достижимостью почтовых серверов или работе серых списков сторонних почтовых серверов. На своё усмотрение можно увеличить таймаут на разумное число, но попытки продолжать доставлять письмо по стандартам RFC нужно несколько дней. Так что думайте и решайте.
Мы не разрешаем собирать карту из того что есть, если вышел таймаут (push_map_as_event_on_timeout => false) и не разрешаем пушить в базу предыдущую карту как событие (push_previous_map_as_event => false)
Скидываем в базу ElasticSearch
Последняя и заключительная секция - output!
Вся часть output (нажмите для раскрытия списка)
# begin output
output {
if "postfix" in [tags] {
# для отладки - если есть ошибки, то скидываем в отдельный текстовый файл
if "_grokparsefailure" in [tags] or "_aggregatetimeout" in [tags] or "_aggregateexception" in [tags] {
file {
path => "/var/log/logstash/fail-postfix-%{+YYYY.MM.dd}.log"
}
} else {
# для отладки скидываем в файл
#file {
# path => "/var/log/logstash/postfix-%{+YYYY.MM.dd}.log"
# flush_interval => 0
#}
# скидываем в базу ES
elasticsearch {
hosts => "localhost"
manage_template => false
index => "postfix-%{+YYYY.MM.dd}"
}
}
# end grok parse falure tags
}
# end postfix tags
}
# end output
Если grok на какие-то строки ругался и добавил свой тег _grokparsefailure ИЛИ в результате сбора карты вышли за пределы таймаута (_aggregatetimeout) ИЛИ произошло исключение в процессе агрегации (_aggregateexception), то скидываем такие события в файл для дальнейшего разбирательства и улучшения парсинга.
Если всё хорошо, то событие отправляем в базу ElasticSearch.
Итог
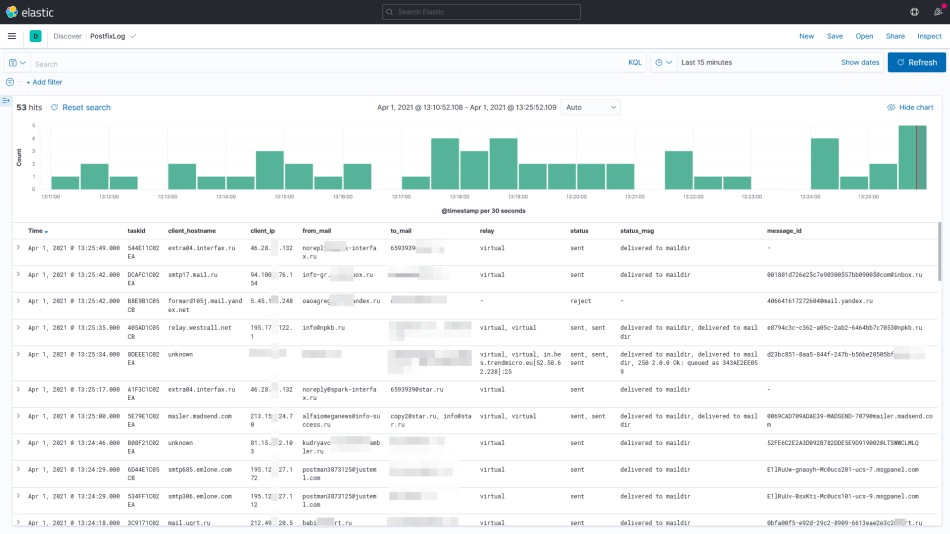
Если всё получилось, то можно в разделе Discover наблюдать поступающие и разобранные события в режиме реального времени. С помощью языка запросов Kibana Query Language (KQL) или Lucene вы теперь не ограничены чьим-либо интерфейсом. Вы можете вести любую аналитику на что хватит вашей фантазии. Строить любые срезы за любое время.
Строить свои графики и компоновать свои dashboard. Один раз создав нужные графики, можно быстро получать актуальную информацию.
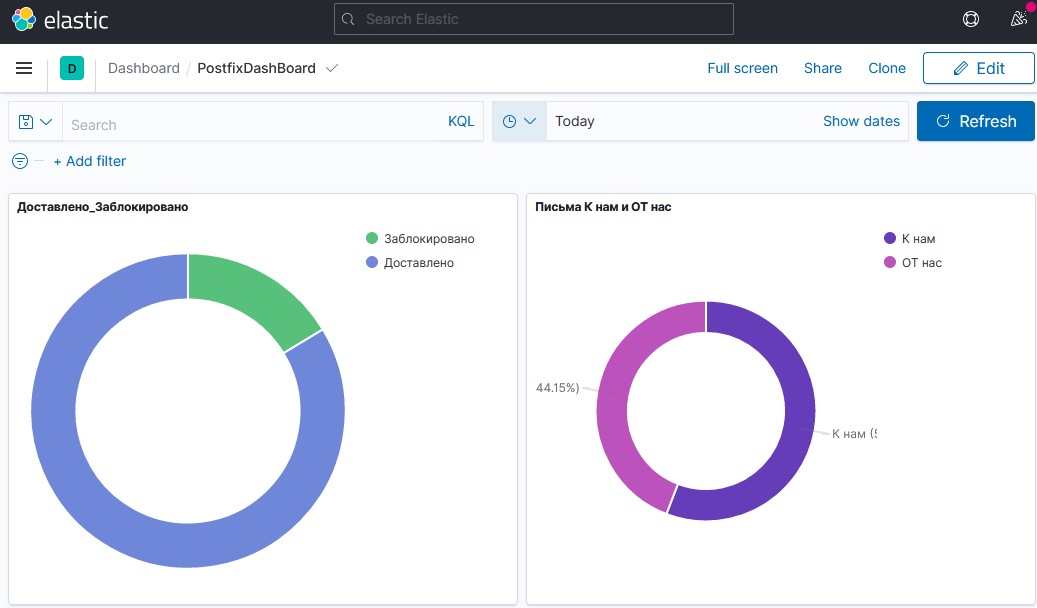
Если есть желание, то можно легко добавить geoip в событие и у вас будет поле "страна адресата". Если тема статьи вам понравилась, то берите смело и развивайте дальше под свои нужды.
Дополнительные материалы:
Архив наработки postfix-logs-2-elasticsearch.tar.gz
Logstash Reference - Filter plugins - Aggregate filter plugin.
Kwaio’s blog. Aggregating postfix logs with Logstash.
