Обновление Proxmox VE 3.4 до 4.
К сожалению, в русском языке плохо передаётся разница между плановым обновлением в рамках релиза (update) и прыжком на другую версию (upgrade). ProxmoxVE нужно было обновить с версии 3.4 на 4, а под его капотом Debian 7 на Debian 8, так чтобы никто не заметил.
Чтобы никто не заметил, это я загнул, ибо сказано, что:
- Не работает кластер серверов под управлением различных Proxmox VE. Это автоматически означает, что ваш кластер вы не обновите без downtime.
- Удалён OpenVZ.
- Новый менеджер High Availability, заменяющий RGmanager.
Самая главная официальная статья Upgrade from 3.x to 4.0. Прежде чем начать, нужно сделать самое главное - резервные копии всего и вся! Нужно сделать резервные копии виртуальных машин, копию /etc/ и /var/lib/pve-cluster/.
Шаги обновления.
Я буду писать вам команды из официальной вики с моими заметками, которые надеюсь будут вам полезны.
1. Обновитесь сначала в рамках релиза. apt-get update && apt-get dist-upgrade
2. Обязательно перезагрузка shutdown -r +0
3. Удалите пакеты старого Proxmox VE - apt-get remove proxmox-ve-2.6.32 pve-manager corosync-pve openais-pve redhat-cluster-pve pve-cluster pve-firmware
4. Замените Wheezy (Debian 7) на Jessie (Debian 8) и УДАЛИТЕ любые строки репозиториев с упоминанием backports, если они есть! В файле /etc/apt/sources.list.d/pve-enterprise.list закомментируйте единственную строку платного репозитория, если вы его не используйте. Не рекомендую удалять сам файл, так как его новую версию вам всё равно подкинут позже. Лучше пусть выведут запрос в ходе обновления!
sed -i 's/wheezy/jessie/g' /etc/apt/sources.list
sed -i 's/wheezy/jessie/g' /etc/apt/sources.list.d/pve-enterprise.list
5. Заберите новые списки пакетов apt-get update
6. Нужно установить новое ядро. На дату написания моей статьи (23.11.2015) это было ядро pve-kernel-4.2.3-2-pve. Рекомендую вам сделать симулирующую установку - sudo apt-get -s install pve-kernel-4* и вам покажут, какие linux ядра из 4 ветки могли бы поставиться. Выберите самое новое и поставьте вместе с пакетом pve-firmware:
Я ставил apt-get install pve-kernel-4.2.3-2-pve pve-firmware
7. Обновляемся до Debian 8. Рекомендую сначала скачать пакеты apt-get -d dist-upgrade
Ставим скачанное и контролируем процесс.
apt-get dist-upgrade
Один из вопросов будет о новой версии OpenSSH и запрете входа root. Я ответил отрицательно (то есть разрешил) для такой системы как ProxmoxVE, хотя приветствую для остальных серверов.
8. Обязательно перезагрузка shutdown -r +0
9. Проверьте версию ядра, системы uname -a && cat /etc/os-release
10. Ставим Proxmox VE 4. apt-get install proxmox-ve
11. OpenVZ больше нет. Если вы их использовали, то должны будете пройти этап конвертации в LXC. Удаляем больше не нужное.
dpkg --purge vzctl
dpkg --purge redhat-cluster-pve
12. Удаляем старые ядра apt-get remove pve-kernel-2.6.*
13. Прибираемся apt-get autoremove; apt-get autoclean
14. Финальная перезагрузка shutdown -r +0
Проблемы Proxmox VE.
Так как избежать downtime не получится, мне пришла гениальная по своей простоте мысль - нужно выключить виртуальные сервера, чья работа не представляет особой важности для работы пользователей. Оставшийся важный набор серверов был перегнан на node1, не прерывая их работу с помощью Live Migration. Начал я обновление своего маленького кластера из 3 нод - задом наперёд ... 3 ... 2 ... 1.
Файл и фэйл.
Первая моя ошибка состояла в том, что понадеявшись на node1, я решил ускорить весь процесс обновления и обновлял node3 и node2 почти одновременно. И получил ситуацию, что важнейший каталог /etc/pve/ был у них или пуст или частично заполнен. GREPанье логов вывело на первопричину - file is encrypted or is not a database. Важнейший sqlite-файл /var/lib/pve-cluster/config.db на нодах 3 и 2 был явно мал и намекал, что он не хранит мою информацию. Ещё оказалось, что там и не sqlite файл, а sql-файл. Midnight Commander со своим F3 только сбил меня с толку.
echo "pragma integrity_check;" | sqlite3 config.db
выдавало, что действительно передо мной не sqlite файл.
Вторая моя ошибка состояла в том, что я не сделал резервную копию /var/lib/pve-cluster/ и мне стыдно признаться, но я не знал о таком важном файле /var/lib/pve-cluster/config.db, из которого буквально воссоздаётся /etc/pve/ со всеми ключами, файлами, конфами и так далее (Proxmox Cluster file system (pmxcfs)). Мне реально повезло, что Proxmox VE при изменениях делает сам резервные копии в /var/lib/pve-cluster/backup/.
Сделал из последнего sql-файла sqlite-файл.
cat config.sql | sqlite3 config.db
echo "pragma integrity_check;" | sqlite3 config.db
При остановленном проекте Proxmox VE systemctl stop pve-cluster; systemctl stop pvestatd; systemctl stop pvedaemon; systemctl stop pveproxy
подкинул файл config.db и слава ИТ богам всё вернулось "як було".
Французы спасибо! Informatique/Softwares/Proxmox/PVE 2.x - Programmes et services
Мультикаст.
Напомню, что смешивать в работе кластера разные версии Proxmox VE нельзя, пришлось понадеяться на удачу, быстро выключить рабочий набор виртуальных серверов и постараться обновить ноду1 как можно быстрее. Обновилась она нормально и что странно, но проблем с /var/lib/pve-cluster/config.db у неё не было.
По инструкции из официальной вики нужно было воссоздать тот же кластер с тем же именем.
На первой ноде
pvecm create имя-вашего-кластера
на остальных нодах
pvecm add IP-адрес-первой-ноды -force
и тут я увидел, что кластер "не собирается". Паника начала подкрадываться, и холодный пот выступил буквально везде. Часы показывали, что рабочий выход в субботу заканчивается. В воскресенье мне не подписан выход на моё оборонное предприятие и в понедельник тысячи людей придут к разбитому мной корыту. Я решил минимизировать ущерб и, зная что кластер нужен только для Live Migration и "обмену-разговору" между нодами, решил запустить виртуальные машины на тех нодах, на которых они "застряли". Первая нода оказалась перегружена, но выхода нет. По крайней мере счётчик downtime перестал тикать и перестали трещать телефоны, чьи трубки я не поднимал  .
.
В такие моменты, главное мобилизоваться и не поддаваться панике, что сложно. Проксмокс 4 теперь опирается в своей работе на мультикаст Multicast notes
Я начал буквально трясти нашего сетевика и требовать от него клятвы, что между нодами с мультикастом всё в порядке. Спасибо ветке форума Proxmox VE 4.0 Cluster - Multicast problems, которая вывела на
echo 1 > /sys/devices/virtual/net/vmbr1/bridge/multicast_querier
echo 0 > /sys/class/net/vmbr1/bridge/multicast_snooping
Ноды увидели друг друга, и кластер собрался. Уф, я склеил корыто, которое сломал сам. Тут я увидел перед собой принесённый хлеб на обед и подумал, что по своей старческой рассеянности забыл его съесть. Но оказалось, что я забыл и пообедать, настолько проблемы при обновлении вытеснили все мысли .
Ещё вам вдогонку Proxmox VE 4.x Cluster
Как правильно править старый конф, но помните, что сейчас CoroSync 2.x хранит информацию о кластере в другом месте - General HowTo for editing the cluster.conf
Вам хорошего обновления без проблем! А меня скоро ждёт опасный прыжок при обновлении кластера Ceph 0.9 Hammer на Ceph 9 Infernalis, который хранит "жёсткие диски" виртуальных машин.
Мой маленький кластер Proxmox VE и Ceph.
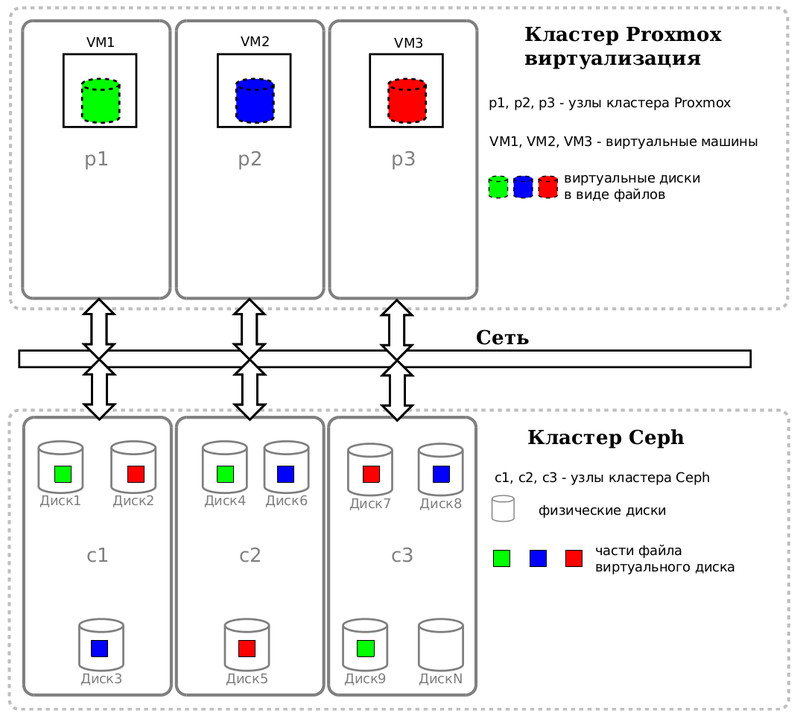
Материалы по теме:
Балансировка виртуальных машин.
Как Proxmox работает с Ceph. RBD.
Оптимизация гостевых операционных систем KVM.
Отдайте моё назад. Механизм discard.
Замена сбойного диска в корне ZFS RAID 1 Proxmox 3.4.
Оптимизация виртуальных серверов.
