Ceph. Часть 1.
Вступление. Приготовление. Создание кластера.
Вступление.
Мониторы Ceph (Ceph Monitors) поддерживают главную копию (master copy) кластерной карты (cluster map), по которой клиенты Ceph могут определить расположение всех мониторов, OSD демонов и серверов Metadata (MDS). До того как клиенты начнут что-либо писать или читать у OSD или MDS, они должны в первую очередь связаться с монитором Ceph.
С текущей кластерной картой и алгоритмом CRUSH, клиенты могут вычислить расположение любого объекта. Эта способность позволяет клиентам напрямую общаться с OSD, что является важным аспектом в архитектуре Ceph и его способности к высокой доступности и производительности.
Главная задача мониторов - поддерживать главную копию кластерной карты. Помимо этого мониторы занимаются аутентификацией и журналированием. Кластерная карта - это комплексная карта. Она состоит из карты мониторов (monitor map), карты OSD (OSD map), карты плейсмент-группы (placement group map) и карты MDS (metadata server map).
В кластере может быть один монитор, но он сразу станет единой точкой отказа (single-point-of-failure). Для обеспечения высокой доступности нужно запускать множество мониторов на различных нодах. Необязательно, но желательно, чтобы количество мониторов в вашем кластере было нечётным числом для улучшения работы алгоритма Paxos при сохранении кворума. В идеале, разработчики Ceph советуют ноды-мониторы не совмещать с нодами OSD, так как мониторы активно используют fsync() и это пагубно влияет на производительность OSD.
Следует знать об архитектурной особенности мониторов. Ceph накладывает жёсткие требования согласования для монитора, когда тот разыскивает другие мониторы в кластере. Другие демоны Ceph и клиенты используют конфигурационный файл для обнаружения мониторов, сами мониторы используют для этого карту мониторов (monmap), а не конфигурационный файл. Использование monmap вместо конфигурационного файла Ceph позволяет избежать ошибок, которые могут привести к разрушению кластера (например, в результате опечатки в ceph.conf при указании адреса монитора или порта). Тем более, что конфигурационный файл Ceph обновляется и распространяется человеком, а не автоматически, и мониторы могли бы не преднамеренно использовать старую версию конфигурации.
OSD (object storage daemon) — в каждой ноде кластера может быть несколько дисков и на каждый диск нужен отдельный демон OSD.
В традиционной архитектуре клиент общается с неким центральным компонентом (шлюз, брокер, API и так далее), который сразу становится единой точкой отказа этой сложной системы. Так же обычно центральный элемент является бутылочным горлышком в плане производительности. Ceph избавляется от центрального элемента в своей структуре, позволяя клиентам общаться с OSD демонами напрямую с помощью алгоритма CRUSH.
Демоны Ceph OSD сохраняют данные в виде объектов в плоском пространстве имён, то есть без иерархии в виде каталогов. Объекты обладают идентификаторами, бинарными данными и метаданными в виде ключ-значение, которые использует MDS сохраняя владельца файла, время создания, время модификации и так далее. Идентификатор объекта уникален в пределах кластера.
Демон OSD в составе кластера постоянно сообщает о своём статусе - up или down. Если по ряду причин OSD демон не сообщает о своём состоянии, демон монитора периодически сам проверяет статус OSD демонов и уполномочен обновлять кластерную карту и уведомлять других демонов мониторов о состоянии OSD демонов.
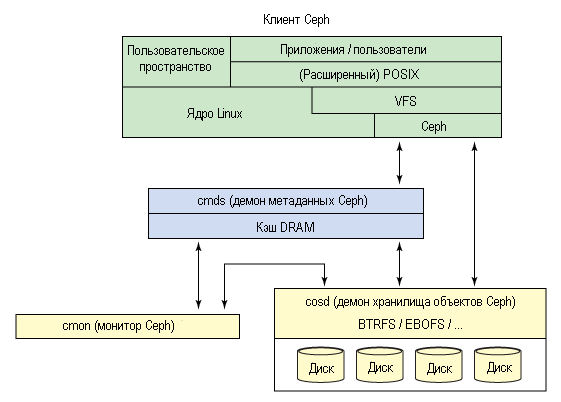
Metadata server (MDS) — вспомогательный демон для обеспечения синхронного состояния файлов в точках монтирования CephFS. В один момент времени работает только один MDS в пределах кластера, а другие находятся в режиме ожидания и кто-то станет активным, если текущий MDS упадёт.
Приготовление.
В официальных руководствах Ceph используется админская нода (в данной статье это ceph1.intra.net), она же первый клиент будущего кластера, поэтому кроме серверов-нод вашего кластера ceph подготовьте и её.
1. В современных версиях ceph желательно все манипуляции с кластером производить утилитой ceph-deploy. На админской ноде создайте каталог /my-cluster, в котором будут обитать файлы-ключи и конфигурационный файл кластера ceph.
mkdir /my-cluster && cd /my-cluster
Желательно команду ceph-deploy использовать без sudo в учётной записи ceph, находясь в каталоге /my-cluster админской ноды, так вы избежите множества проблем.
2. На всех нодах должен быть установлен OpenSSH sudo apt-get install openssh-server, так как утилита ceph-deploy будет с админской ноды по вашим запросам выполнять нужное на нодах.
3. На каждой ноде должен быть создан пользователь ceph и на каждой ноде должно быть сделан файл /etc/sudoers.d/ceph, позволяющий пользователю ceph выполнять через sudo любые команды без запроса пароля.
echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph
sudo chmod 0440 /etc/sudoers.d/ceph
4. Желательно на админской ноде создать у пользователя ceph файл ~/.ssh/config с содержимым, где cephN.intra.net это ноды вашего будущего кластера.
Host ceph1 Hostname ceph1.intra.net IdentityFile /home/ceph/.ssh/id_rsa User ceph Host ceph2 Hostname ceph2.intra.net IdentityFile /home/ceph/.ssh/id_rsa User ceph Host ceph3 Hostname ceph3.intra.net IdentityFile /home/ceph/.ssh/id_rsa User ceph Host ceph4 Hostname ceph4.intra.net IdentityFile /home/ceph/.ssh/id_rsa User ceph ...
Имена вида cephN.intra.net должны резолвится нормально в вашей сети всеми нодами.
5. На админской ноде нужно добавить репозиторий ceph. На дату написания статьи актуальной версией ceph был релиз firefly 0.80.
Добавляем ключ и репозиторий
wget -q -O- 'https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' | sudo apt-key add -
echo deb http://ceph.com/debian-firefly/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
6. На админской ноде установите ceph-deploy и ceph-common
sudo apt-get update && sudo apt-get install ceph-deploy ceph-common
7. Если не создавали, то создайте ключ с помощью ssh-keygen и пустой passphrase. С помощью ssh-copy-id скопируйте ваш ключ на все ваши ноды, чтобы в дальнейшем была возможность заходить на них без ввода пароля.
8. Настройте синхронизацию времени среди нод вашего кластера. Это очень важно!
9. Все ноды кластера ceph должны иметь возможность вытянуть свой ключ с помощью wget, поэтому предоставьте данную возможность, хотя бы через прокси.
Создание кластера.
Основная статья CREATE A CLUSTER и STORAGE CLUSTER QUICK START.
Начиная от простого и переходя к сложному, попробуем создать первый кластер из трёх нод, на которых будет запущены мониторы. Находясь в каталоге /my-cluster вызывайте ceph-deploy new ceph2 ceph3 ceph4
Подробности команды можно получить ceph-deploy new -h. По умолчанию имя кластера будет ceph. Если вы хотите на одном и том же оборудовании использовать несколько кластеров, то для каждого из них нужно задавать имя, используя ceph-deploy --cluster {cluster-name} new ...
Пока нам не нужна возможность множества кластеров, поэтому опустив параметр --cluster мы получили дефолтное имя ceph и файлы: начальная конфигурация кластера ceph.conf, журнал ceph.log, ключи ceph.mon.keyring
Если что-то идёт не так, всегда просматривайте журнал ceph.log на предмет возможных ошибок. Если вы пропустили 7 пункт приготовления и не скопировали ключи на свои ноды, то знайте, что ceph-deploy new копирует ключи, но только на указанные ему ноды-мониторы. В будущих примерах мы будем добавлять другие ноды и необязательно мониторы и поэтому не следует пропускать 7 пункт для новых нод.
Если на любом из этапов у вас возникнут проблемы, то вы всегда можете начать сначала. Для этого вызывайте для своих нод
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
ceph-deploy purge {ceph-node} [{ceph-node}]
