Инструменты манипулирования файлами PDF.
Многие знают о формате Portable Document Format, благодаря которому мы видим на различных платформах документ так как его задумал автор. Чаще всего нам нужно просто прочесть какое-либо руководство в формате PDF и в Linux есть масса программ для просмотра. А что если нужно не только прочесть pdf файл?
что такое пдф?
Это прежде всего формат документа (Portable Document Format (PDF)), который был придуман фирмой Adobe Systems. Формат пдф был задуман как межплатформенный открытый формат электронных документов, что означает для пользователя избавление от массы проблем. Если вы видите документ в формате pdf на экране вашего устройства, то точно так же он будет выглядеть при печати. Вас не будут волновать размер полей, наличие шрифтов в системе и т.д. На практике, всё не так радужно, но, в целом, документы пдф вызывают меньше проблем, чем остальные. Не даром, формат пдф стал стандартом распространения различных справочных руководств. Считается хорошим тоном отправлять документы в формате pdf вашим адресатам, если не подразумевается дальнейшая правка. Формат пдф включает в себя механизм электронных подписей для защиты и проверки подлинности документов, что позволяет легко убедиться в авторстве документа.
pdfgrep. Поиск в pdf.
Если вы хоть раз использовали мощную утилиту grep, то вам сразу будет ясна работа pdfgrep. Отличие только одно. Grep оперирует строками, а PdfGrep страницами. PdfGrep умеет использовать мощь регулярных выражений, обходить рекурсивно каталоги при поиске, подсвечивать найденное.
comparepdf. Сравнение файлов pdf.
Утилита командной строки comparepdf, как говорит её имя, создана для сравнения pdf файлов. По умолчанию сравнение происходит в "текстовом" режиме (подразумевается --compare=text), где сравнивается текст соответствующих пар страниц. При нахождении различий программа выводит сообщение и возвращает код выхода.
Опция --compare=appearance позволяет "узнать" нет ли изменений в диаграммах или изображениях. Опции -verbose=0 отключают сообщения, -verbose=1 сообщают только при различии, -verbose=2 сообщают при различии или идентичности.
Вам стоит знать, что comparepdf не выводит вам в каком-либо виде различающиеся части. Утилита заточена под вызовы из программ для диагностирования самого факта различия или идентичности в pdf. Если вам необходим инструмент визуального сравнения документов, то переходите к Diffpdf.
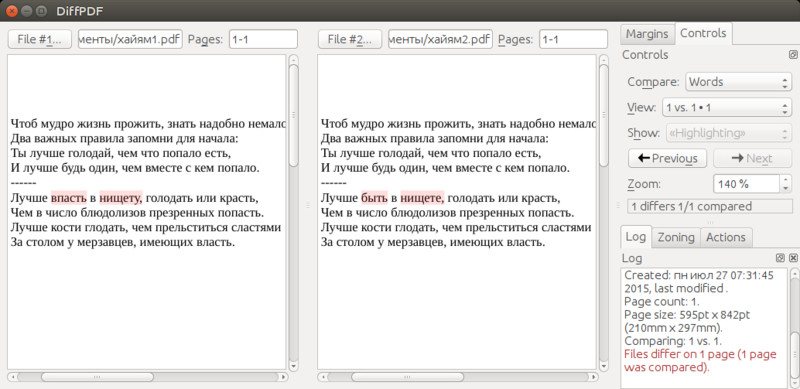
Diffpdf.
DiffPDF используется для сравнения двух файлов формата PDF. По умолчанию в каждой паре страниц сравнивается текст, но можно сравнить и внешний вид. Например, изменение вставленной диаграммы или стиля абзаца. Кроме того, можно сравнить определённые страницы или страницы в определённых диапазонах. Например, если в первой версии файла формата PDF имеются страницы от 1 до 12, а во второй - от 1 до 13 (вставлена дополнительная страница 4), эти версии можно сравнить, страницы первой версии файла указав в диапазоне 1-12, а страницы второй — в диапазонах 1-3 и 5-13. Таким образом, DiffPDF выполнит сравнение страниц в следующих парах: (1,1), (2, 2), (3, 3), (4, 5), (5, 6) и далее до (12, 13).
Картинки в pdf.
Если у вас есть серия изображений типа pic_*.jpg, то преобразовать в pdf можно командой ls -v | tr '\n' ' ' | sed 's/$/\ result.pdf/' | xargs convert Причём pic_10.jpg будет после pic_9.jpg, а не после pic_1.jpg, благодаря ключу -v.
PDF Toolkit (pdftk).
Если PDF документ - это "электронная бумага", то pdftk - это степлер, дырокол, сшиватель в одном флаконе. pdftk, словно швейцарский нож, умеет:
- Соединить множество pdf в один.
pdftk file1.pdf file2.pdf cat output newFile.pdfилиpdftk *.pdf cat output combined.pdf - Разделить один pdf на множество.
pdftk user_guide.pdf burst - Удалить часть страниц из документа pdf. Для примера удалим с 10 по 25 страницу.
pdftk myDocument.pdf cat 1-9 26-end output removedPages.pdf - Расшифровать документ pdf.
pdftk secured.pdf input_pw ВашПароль output unsecured.pdf - Зашифровать документ pdf.
pdftk your_normal.pdf output secured.pdf owner_pw ВашПароль - Попробовать исправить повреждённый документ pdf.
pdftk broken.pdf output fixed.pdf - Вращение страниц в документе pdf. Повернуть первую страницу в документе pdf на 90 градусов по часовой стрелке
pdftk in.pdf cat 1east 2-end output out.pdf. Повернуть все страницы на 180 градусовpdftk in.pdf cat 1-endsouth output out.pdf - Нанести на страницы в документе pdf "водяной знак". Для примера нужно на каждой странице сделать указание что это Черновик. Сделайте draft.pdf из одной страницы со словом Черновик. Командуйте
pdftk document.pdf background draft.pdf output watermark_document.pdf - Обновить метаданные pdf. Например, можно создать текстовый файл War_Peace.txt с содержимым
InfoKey: Title InfoValue: Война и Мир InfoKey: Author InfoValue: Л.Н. Толстой InfoKey: Keywords InfoValue: Россия,1869,романpdftk war_peace.pdf update_info war_peace.txt output war_peace-updated.pdf - Умеет заполнять PDF Forms с FDF Data или Flatten Forms.
Из PDF в текст. Конвертер PDF.
Вызов pdftotext document.pdf document.txt позволит вам извлечь текст из pdf. Можно сразу вывести текст в простой html или xml. Если текст в pdf есть на фиксированных позициях, то есть возможность указать координаты и текст будет извлечён именно оттуда. Вызывая pdftotext document.pdf - | grep НужнаяСтрока, можно сымитировать работу pdfgrep.
Из PDF вытащить картинки.
Вызов pdfimages -j document.pdf images/ приведёт к тому, что в подкаталоге images/ будут находиться извлечённые файлы в формате PBM для монохромных изображений и PPM для цветных. Опции -png, -tiff, -j, -jp2 и -jbig2 сохранят соответственно в форматах PNG, TIFF, JPEG, JPEG2000 и JBIG2.
Из CHM в PDF.
Если хотите преобразовать свою коллекцию различных руководств в формате Microsoft Compiled HTML Help в Portable Document Format, то в этом поможет утилита командной строки chm2pdf. chm2pdf поддерживает пакетный режим, опции безопасности PDF, защиту паролем и режимы сжатия.
PDF Split and Merge (pdfsam).
Нельзя не отметить java программу PDF Split and Merge (pdfsam), которая в графическом режиме позволит сделать массу вышеописанного.
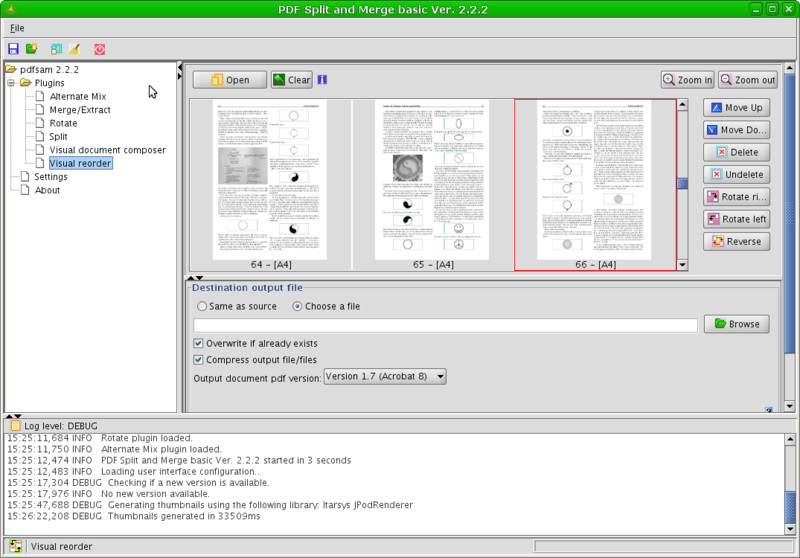
PDFSaM идёт в двух версиях, обе свободны. Базовая доступна в пакетах для Debian, Ubuntu и Arch Linux. Расширенная версия обладает всем функционалом, но доступна на официальном сайте лишь в виде исходного кода, хотя учитывая язык java, проблем с запуском программы быть не должно.
Базовая версия:
- Позволит разделить PDF на множество страниц, каждую в свой файл.
- Извлечение выбранных страниц в новый PDF.
- Соединить несколько документов PDF в один.
- Вращать страницы в документе PDF.
- Визуально изменить порядок следования страниц.
- Визуально создать новый PDF из нескольких PDF, вручную перетаскивая нужные страницы.
Расширенная версия:
- Шифровать и дешифровать PDF.
- Устанавливать права доступа.
- Извлекать вложения (attachments).
- Обновлять метаданные.
Дополнительные материалы:
Свободные форматы файлов.
