Операция Прыжок.
Русский язык богат и красив, но вот иногда есть события в мире ИТ, которых на русском языке сложно передать, не потеряв оттенки. Английские update и upgrade специалистам легко и просто объясняют штатность процедуры в случае update и серьёзное изменение с переходом нумерации версии в случае с upgrade. На русском языке - всё обновление. Речь пойдёт об обновлении системы хранения данных из класса software-defined storage по имени Ceph, который сменится с версии 0.94.9 Hammer на 10.2.5 Jewel. Новая версия Ceph 10.2 Jewel подразумевает целиком и полностью, что системой инициализации у вас является systemd. Это автоматически означает необходимость обновить Ubuntu 14.04 LTS на Ubuntu 16.04 LTS. Как прошло обновление? Кратко - хорошо, но я постарел на пару лет.
В нашей схеме кластер Ceph нужен кластеру Proxmox VE, как единое СХД, чтобы виртуальные машины могли в онлайн режиме мигрировать с одной физической ноды на другую без прерывания обслуживания пользователей.
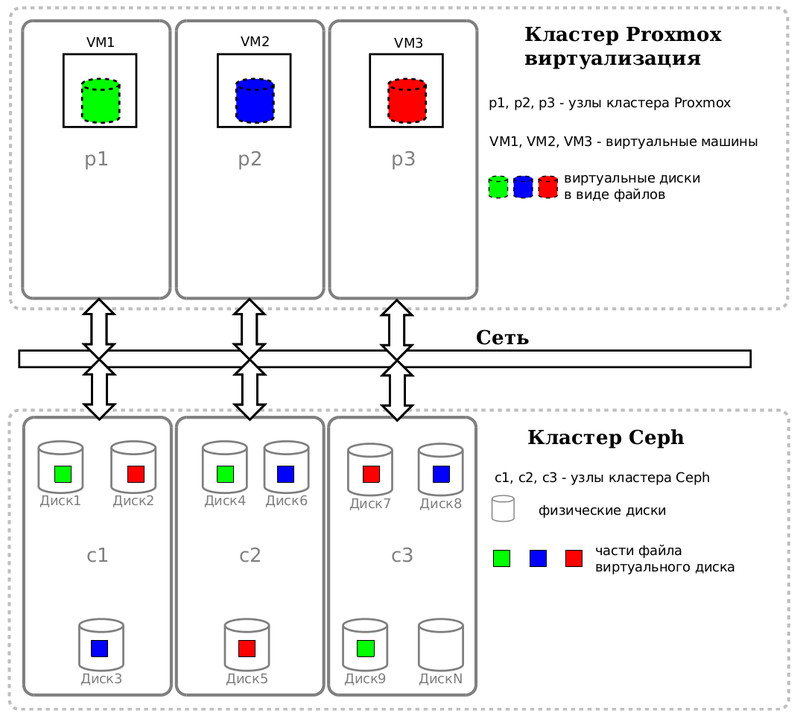
Наглядное видео про Live Migration в ProxmoxVE.
Самая главная статья V10.2.0 JEWEL RELEASED, с которой нужно начать знакомство. Самое важное в новом релизе, помимо вкусняшек, демоны теперь работают от пользователя ceph, а не от root. Если в системе уже существует данный пользователь, то вам придётся сделать дополнительные телодвижения. В своё время создавал пользователя cu (Ceph User) и на данном требовании только спокойно выдохнул, что не нужно париться по данному поводу. Для тех кто не хотел бы на таком сложном этапе забивать голову сменой владельца, можно указать setuser match path = /var/lib/ceph/$type/$cluster-$id в /etc/ceph/ceph.conf и тогда Ceph не будет сбрасывать привилегии и по старинке будет работать от root.
Сначала дам пункты действий, которые накидал себе, чтобы в суете не забыться и не сделать опасных шагов. Сразу скажу, что они помогли, но это теория, а на практике пришлось дополнительно шлифовать напильником.
Обновление Ubuntu 14.04 до Ubuntu 16.04 и Ceph 0.94.9 Hammer до Ceph 10.2.5 Jewel.
- Обновляем сервер за сервером в рамках релиза
sudo apt update && sudo apt upgrade - Перезагрузка серверов.
- Упаковка каталога /etc/
- Подготовка к обновлению платформы Ubuntu 14.04 до 16.04. В файле /etc/apt/sources.list замена trusty на xenial
- Подготовление к обновлению Ceph 0.94 Hammer до Ceph 10.2 Jewel.
В файле /etc/apt/sources.list.d/ceph.list
строку deb http://de.ceph.com/debian-hammer/ trusty main
заменить на deb http://de.ceph.com/debian-jewel/ xenial main - Остановка демонов ceph в Ubuntu 14.04 через систему инициализации Upstart -
stop ceph-all - Переход на новые версии плаформы Ubuntu и Ceph -
sudo apt update && sudo apt -d dist-upgradeиsudo apt dist-upgrade - Проверка наличия пользователя ceph в системе
grep ceph /etc/passwd - Исправление прав доступа. Назначение владельцем следующих каталогов
sudo chown -R ceph:ceph /mnt/
sudo chown -R ceph:ceph /var/lib/ceph/
sudo chown -R ceph:ceph /etc/ceph/ - Монтирование всех дисков обратно в /mnt/ и проверка владельца у /mnt/. Владельцем должен быть пользователь ceph.
- Перезагрузка серверов по одному.
- Проверка новой системы инициализации systemd
- Проверка остановки и старта всех демонов
systemctl stop ceph.target && systemctl start ceph.target - Проверка статуса работоспособности
systemctl status ceph-osd@1 - Проверка наличия в памяти демонов
ps auxxw | grep ceph - Проверка работоспособности Ceph
ceph -wиceph osd tree - Выставление бита —
ceph osd set sortbitwise
Проблемы, ошибки, просчёты
sudo chown -R ceph:ceph /mnt/. Ошибкой было сменить владельца одной командой для кучи дисков, которые примонтированы в данную точку. В моём случае там были /mnt/d1/, /mnt/d2/, /mnt/d3/. Так как объёмы исчисляются терабайтами, то chown обходила каталоги рекурсивно и в одну единицу времени "работал" один диск. Лучше было бы запустить в фоне для каждого диска свою команду и затратить на итоговую операцию гораздо меньше времени. Львиная доля потерянного времени пришлась как раз на ожидание смены владельца.- Не проблема, но нужно быть к этому готовым и держать перед глазами вашу текущую схему - какие OSD и на каких серверах запущены. Переход с Upstart на SystemD не означает, что автоматически все сервисы будут включены и активированы. Готовьтесь делать systemctl enable ceph-mon@имя-ноды и systemctl enable ceph-osd@номер-диска. В моём плане этого не было, что означает просчёт. Частично меня извиняет тот факт, что на тестовом полигоне проверял переход Ubuntu 14.04 -> 16.04 и Ceph 0.94 Hammer -> 9 Infernalis, но это было давно. Когда сел пробовать Ubuntu 14.04 -> 16.04 и Ceph 0.94 Hammer -> 10 Jewel, оказалось что очень важная утилита ceph-deploy была сломана в своей последней версии и было невозможно развернуть Молот на тестовом полигоне с нуля. Моя ошибка заключалась в том, что обновление существующего кластера было не до конца проверено в тестовой среде.
- Недостаточно исчерпывающая информация от проекта Ceph в разделах UPGRADING FROM INFERNALIS OR HAMMER и UPGRADING FROM HAMMER. В них было упоминание про флаг sortbitwise, но ничего не сказано про флаг require_jewel_osds, который пришлось возвести, чтобы кластер перешёл из HEALTH_WARN в состояние HEALTH_OK.
- Само обновление системы через dist-upgrade показало в очередной раз железобетонность команды, которая никогда ещё не подводила. Операционная система и сам ceph сменили свои версии, но серьёзной ошибкой было рассматривать кластер ceph отдельно от всей аппаратно-программной системы - кластер ProxmoxVE, как клиент-потребитель, и кластер Ceph, как сервер-поставщик. Proxmox VE просто не увидел обновлённый Ceph. С тяжёлым сердцем, замыленным взглядом, красными глазами, пришлось оставить попытки исправить ситуацию и после 10 часов всей процедуры обновления, уйти с родного предприятия в 23:00, оставив его по сути в руинах. Кластер виртуализации Proxmox VE не сможет запустить виртуальные машины, так как их "жёсткие диски", лежащие в СХД Ceph, недоступны. Через пару часов кошмарного сна, вернувшись утром на родное предприятие был составлен с коллегами "план отхода". Нужно было развернуть минимальный набор самых важных виртуальных серверов из резервной копии, разместив "жёсткий диск" данной виртуальной машины на локальном жёстком диске Proxmox VE, устраняя Ceph из схемы. Не успев приступить к плану, решил сделать последнюю попытку исправиться и всё реанимировать. GUI хорош - когда всё хорошо, когда всё плохо нужна консоль. Proxmox VE через librbd видит Ceph через абстракцию RBD (RADOS Block Devices). В консоли одного из серверов Proxmox VE решил посмотреть на вывод команды
rbd -m IP_mon_ceph -p rbd ls, которая должна вывести список "жёстких дисков". Ошибка прямо говорила что не совпадают наборы возможностей (feature set mismatch). Обновлённый Ceph умеет то, что не знакомо ещё Proxmox VE через его librbd. И тут в очередной раз хочется сказать спасибо Ceph за то какой он крутой. Одна команда спасла меня от расстрела -ceph osd crush tunables hammer. Для Proxmox VE 4.4 кластер Ceph 10 Jewel по возможностям стал аля Hammer. И всё заработало!
Выводы
- Всегда помнить про целостность всей системы. Не воспринимать кластер Ceph, как СХД, отдельно от системы виртуализации ProxmoxVE. Тщательнее следить за информацией от разработчиков ProxmoxVE о состоянии готовности его взаимодействия с различными СХД типа ceph и glusterfs.
- Впредь при работе на серверах Ceph в будущем, все команды Linux, работающие непосредственно с файлами и папками, тщательно обдумывать, чтобы задействовать паралелльно все диски одновременно. Помнить про огромные размеры. Думать терабайтами.
- Понизить в себе до минимума это гусарское, залихватское ихха. Бо́льше тестирования, бо́льше планирования, бо́льше методичности!
Планы на будущее
Ubuntu 16.04 LTS будет на рынке до 2021 года. Так как LTS релизы у Ceph короче и приблизительно составляют 18 месяцев, то Ubuntu 16.04 LTS надолго останется платформой для следующих релизов Ceph и такого серьёзного прыжка в обновлении уже не будет. Будет обновляться только один Ceph, что легче и проще.
Ceph - это программное решение software defined storage. Главной задачей разработчиков является сохранение данных и сохранять их нужно безопасно. Из-за ограничений файловых систем, решить задачу можно через механизм "журналирования". Но платой служит удвоение процедур записи. Пишем в журнал, фиксируем, потом льём на конкретный диск. Вот почему рекомендуется размещать журнал на отдельном диске и желательно на SSD. Но всё это касается бэкенда FileStore. Разработчики в Ceph 10 Jewel дали экспериментальную возможность пощупать новый backend BlueStore (Block + NewStore).
Самая главная вкусняшка состоит в том, что файловая система теперь не нужна. Вы будете отдавать сырые разделы и демоны OSD будут работать с ними без оверхеда и без всяких грязных хаков.
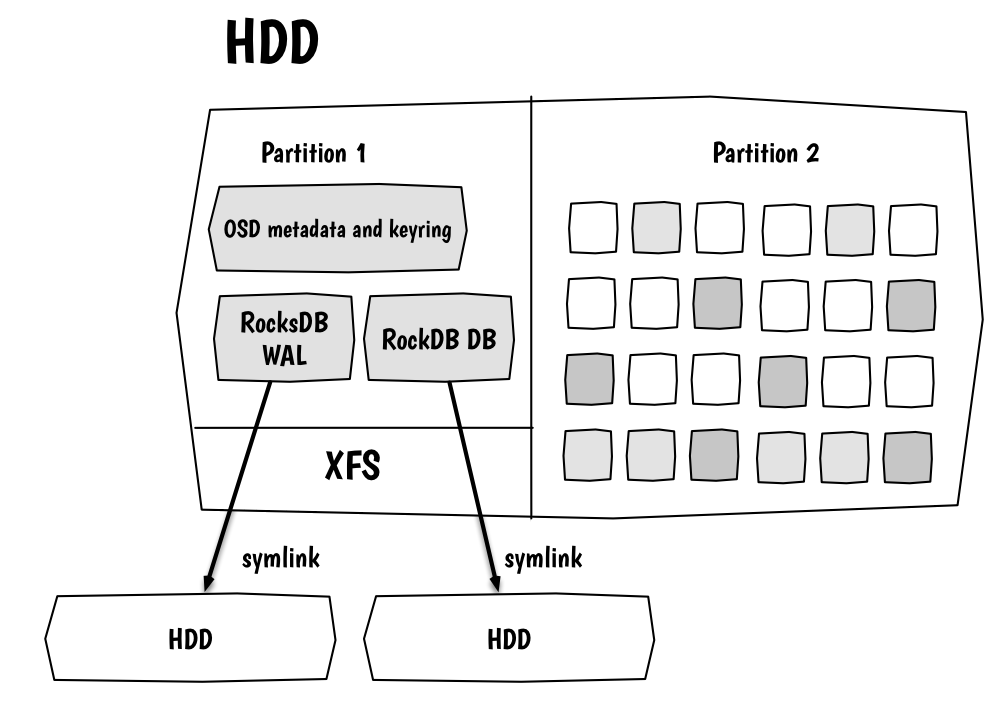
Сейчас рано думать о переходе на BlueStore, но держать руку на пульсе нужно. Когда BlueStore перестанет быть экспериментальной возможностью и разработчиками будет освещён механизм перехода с одного бэкенда на другой, тогда и нам можно будет планировать смену.
Из нереализованных планов осталась возможность добавить ещё сервера (их тупо мне не покупают), но в другом ЦОДе. Если штатными средствами объяснить Ceph какие сервера находятся в каких ЦОДах, то он перебалансирует данные так, чтобы допускать поломку целого ЦОДа без остановки производства.
Также до сих пор не дополнили сервера дисками SSD, чтобы вынести на них журналы и ускорить операции записи ИЛИ сделать через SSD пул под горячие данные, что также благотворно влияет на общую производительность.
Как я первый раз сломал всё - Обновление Proxmox VE 3.4 до 4.
Процедура проверки жёстких дисков в кластере Ceph.
Что не так с файловыми системами? Почему даже Btrfs не поможет? Зачем BlueStore?
